Visão
Para esta competição, foram implementados softwares de visão relativos às tarefas de detecção do portal, dos path markers, das boias e dos personagens. Foram utilizados tanto bibliotecas de visão tradicional (OpenCV), quanto deep learning para a realização das tarefas. A ideia de utilizar o OpenCV teve o intuito de reduzir a utilização das redes neurais para a identificação de certos objetos da competição, considerando que temos à disposição uma placa com um poder de processamento limitado para a tarefa de redes neurais.
Para a melhoria da qualidade e contraste das imagens obtidas a partir do simulador, foram utilizadas algumas técnicas, como a equalização de histograma por limite de ajuste de contraste e a correção Gamma. Esses filtros utilizados auxiliaram na remoção do efeito de esverdeamento e turbidez da água. No apêndice X, podem ser vistas imagens com e sem os filtros para melhorias.
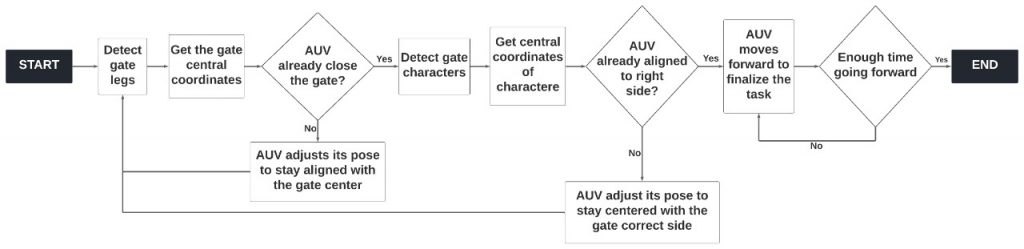
Na detecção do portal e dos marcadores, foram utilizadas ferramentas de segmentação de imagem a partir do modo HSV, além de outras ferramentas de filtragem, bem como ferramentas de extração de contornos. Após a extração dos contornos e aproximação destes por retângulos, a coordenada central deste objeto é mapeada em cada instante de tempo. Também são verificados os tamanhos relativos de cada uma das pernas para a verificação da angulação do AUV em relação ao portal. No apêndice Y, pode ser vista uma imagem exibindo a detecção do portal durante a prova, bem como um fluxograma ilustrando o processo de controle do AUV durante a etapa de passagem pelo portal.
Para os marcadores do fundo da piscina, os contornos desse objeto são extraídos, e a angulação desse objeto em relação a horizontal é checada. Dessa forma, o AUV pode se orientar para partir para a próxima tarefa.





Quanto às detecções dos personagens fixados no portal e das boias, foi utilizada uma solução de deep learning. Optou-se por esse caminho em virtude da maior complexidade dessas tarefas. Com isso,utilizar ferramentas de visão tradicional para esses casos traria muitas dificuldades e a solução obtida não teria grande robustez.
Foi utilizado como base para o dataset da equipe imagens do ambiente simulado da Transdec na Unity, já que não conseguimos realizar testes de visão com o AUV de forma presencial. Após a coleta do dataset, também foi realizado o processo de anotação das imagens.
Na sequência, iniciaram-se os estudos sobre possíveis modelos de redes neurais convolucionais que poderiam ser utilizados, levando em consideração os recursos de hardware disponíveis para a equipe. Foram estudados e testados três modelos, sendo eles: Yolo-v3 Tiny, SSD MobileNet e Faster R-CNN (da biblioteca Detecto). Após os testes realizados, notou-se que o modelo mais preciso era o da biblioteca Detecto. Entretanto, o tamanho da rede neural era muito grande, e nossa placa não seria capaz de carregar em memória o modelo para realizar as inferências.
Sendo assim, optou-se pela utilização de um outro modelo, menos preciso porém mais leve e com inferências mais rápidas. Tanto a Yolo-v3 Tiny quanto a SSD-Mobilenet possuíam estas características, entretanto notou-se que o modelo treinado com a arquitetura SSD estava realizando detecções mais precisas e velozes que o da arquitetura Yolo.
Com isso em mente, foi escolhida a rede neural de arquitetura SSD Mobilenet para a competição, utilizada a partir da API de detecção de objetos do TensorFlow, com o intuito de obter uma precisão razoável com maior velocidade nas detecções, considerando o hardware existente para a equipe.
Com base nos testes realizados no ambiente de simulação Unity, foi possível verificar que o modelo escolhido apresentou bons resultados de detecção. Percebeu-se que o modelo funcionou de forma muito satisfatória para objetos médios e grandes em relação ao tamanho da imagem, mas para objetos pequenos, o modelo enfrenta um pouco de dificuldades, ainda que consiga realizar as detecções. No entanto, realizando as detecções desses objetos menores (personagens do portal), apenas em regiões mais próximas do portal, a instabilidade das detecções conseguiu ser superada. No apêndice Z, temos imagens dos objetos sendo detectadas nas imagens do simulador no ambiente da Transdec.