Vision
For this competition, vision software related to the tasks of detecting the gate, path markers, buoys and characters were implemented. Both traditional vision libraries (OpenCV) and deep learning were used to perform the tasks. The idea of using OpenCV [1] was intended to reduce the use of neural networks for the identification of certain competition objects, considering that we have at our disposal a board with limited processing power for the task of neural networks.
To improve the quality and contrast of the images obtained from the simulator, some techniques were used, such as contrast limited adaptive histogram equalization (CLAHE) [2] and Gamma correction. These filters helped to remove the effect of greening and turbidity of the water. In Appendix X, images with and without filters for enhancements can be seen.
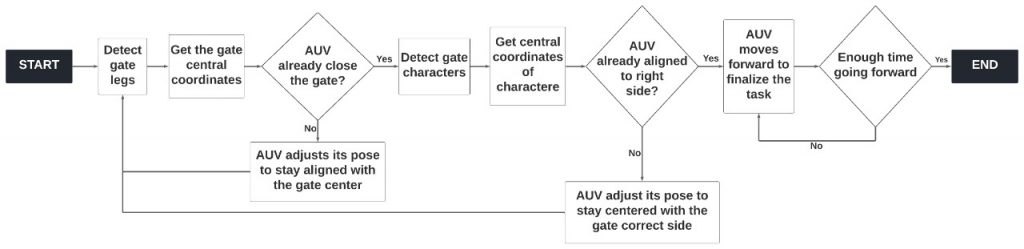
In the gate detection, image segmentation tools were used from the HSV mode, in addition to other filtering tools, as well as contour extraction tools. After extracting the contours and approximating them by rectangles, the central coordinate of this object is mapped at each instant of time. The relative sizes of each of the legs are also verified to check the angulation of the AUV regarding the gate. In Appendix Y, an image showing the detection of the gate during the test can be seen, as well as a flowchart illustrating the process of controlling the AUV during the step of passing through the gate.
For pool bottom markers, the contours of this object are extracted, and the angulation of this object relative to the horizontal is checked. That way, the AUV can orient itself to the next task.





As for the detections of the characters fixed on the portal and the buoys, a deep learning solution was used. This solution was chosen due to the greater complexity of these tasks. Thus, using traditional vision tools for these cases would bring many difficulties and the solution obtained would not be very robust.
Images of the simulated environment of Transdec in Unity were used as a basis for the team's dataset, since we were unable to perform vision tests with the AUV in person. After collecting the dataset, the image annotation process was also carried out.
Subsequently, studies began on possible models of convolutional neural networks that could be used, taking into account the hardware resources available to the team. Three models were studied and tested, namely: Yolo-v3 Tiny, SSD MobileNet and Faster R-CNN (from the Detecto library). After the tests were performed, it was noticed that the most accurate model was the one from the Detecto library. However, the neural network size was too large, and our board would not be able to load the model into its memory to perform the inferences.
Therefore, it was decided to use another model, less precise but lighter and with faster inferences. Both Yolo-v3 Tiny and SSD-Mobilenet had these characteristics, however it was noticed that the model trained with the SSD architecture was performing more accurately and with faster detections than the Yolo architecture.
With that in mind, SSD Mobilenet architecture neural network [3] was chosen for the competition, used from the TensorFlow object detection API [4], in order to obtain a reasonable precision with greater speed in the detections, considering the existing hardware for the team.
Based on the performed tests in the Unity simulation environment, it was possible to verify that the chosen model presented good detection results. It was noticed that the model worked very satisfactorily for medium and large objects in relation to the image size, but for small objects, the model faces some difficulties, even though it manages to perform the detections. However, by performing the detections of these smaller objects (gate characters) only in regions closer to the portal, the instability of the detections was overcome. Appendix Z shows image objects being detected in the simulator images inside the Transdec environment.